一聽到 Stack Overflow 這個名字,
大部分工程師第一個想到的是那個問答網站。
但在嵌入式開發,Stack Overflow 是一個真實會發生的災難,
而且症狀往往讓你完全摸不著頭緒。
程式跑著跑著突然 reset,
某個全域變數的值莫名其妙被改掉,
函式回傳之後跳到奇怪的位址,
或是程式直接進入 HardFault Handler,
然後你盯著 register dump 發愁。
這些症狀背後,很多時候都是同一個原因:
Stack 被寫爆了。
Stack 是什麼,為什麼會 Overflow
Stack 是一塊固定大小的記憶體區域,
用來存放:
- 函式的區域變數(Local Variables)
- 函式呼叫的返回位址(Return Address)
- 函式參數(某些 ABI 下)
- 暫存器的保存值(Context Save)
每次呼叫函式,Stack 就往下長(大部分架構是往低位址方向)。
函式返回,Stack 再縮回去。
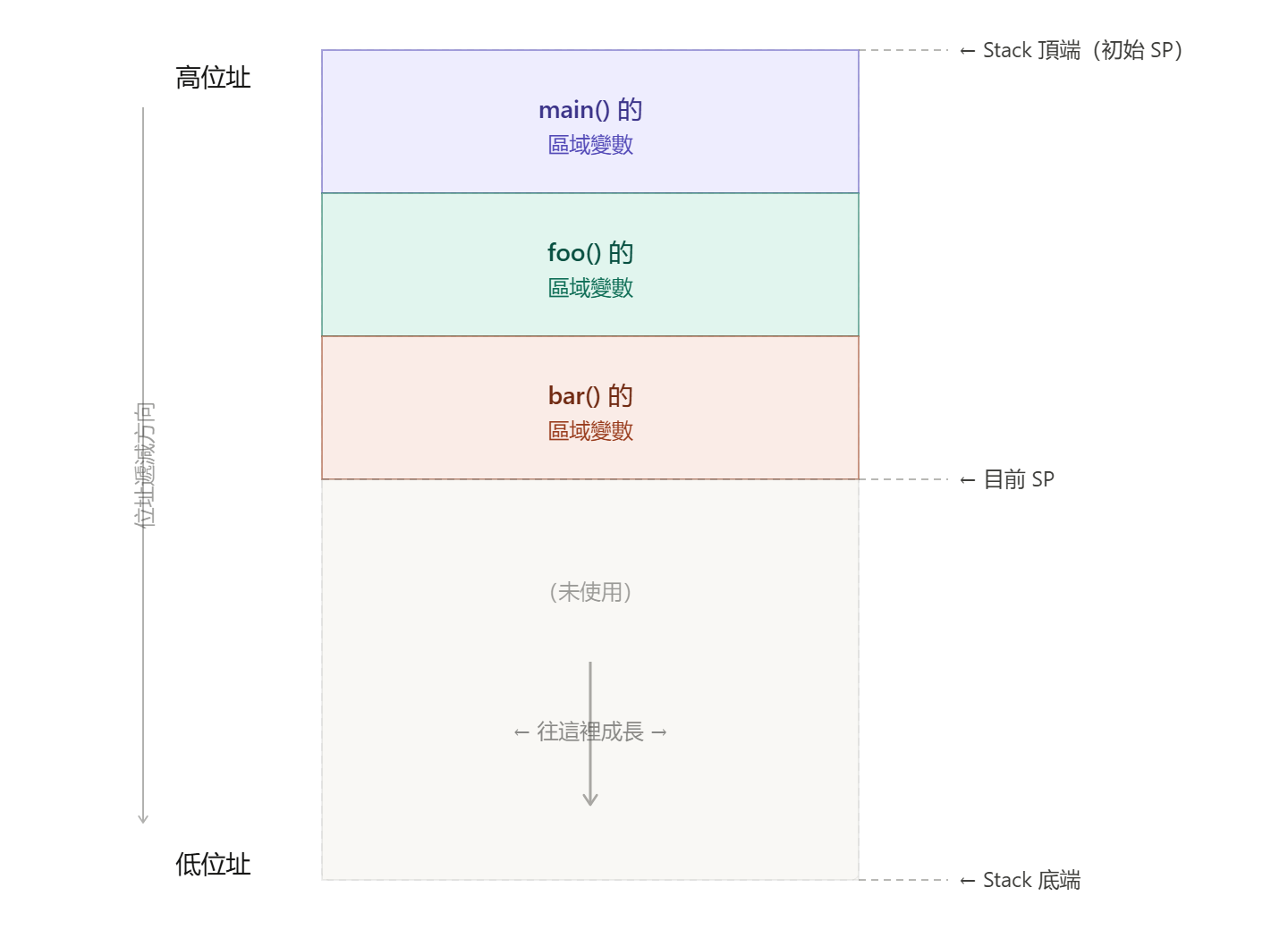
如果 Stack 用完了還繼續往下寫,
就會覆蓋到 Stack 底端以外的記憶體,
那裡可能是 heap、全域變數、或是其他 task 的 Stack。
這就是 Stack Overflow。
嵌入式的 Stack 有多小
在 PC 上,OS 通常給每個執行緒幾 MB 的 Stack,
而且用完了還可以自動擴展(mmap 新的頁面)。
嵌入式完全不一樣:
| 平台 | 典型 Stack 大小 |
|---|---|
| Arduino Uno(ATmega328P) | 2KB(整個 SRAM) |
| STM32F103 | 自己配置,通常 1-4KB |
| ESP32 | FreeRTOS task 預設 2-4KB |
| Raspberry Pi(Linux) | 8MB(跟 PC 差不多) |
幾 KB 的 Stack,一個不小心就滿了。
哪些情況容易爆 Stack
情況一:區域變數太大
void process_frame(void) {
uint8_t frame_buf[4096]; // ❌ 4KB 的區域變數,直接把 Stack 幹掉一半
// ...
}大 buffer 放在 Stack 上是最常見的原因。
解法是改成靜態或全域:
static uint8_t s_frame_buf[4096]; // ✅ 放在 BSS,不佔 Stack
void process_frame(void) {
// 使用 s_frame_buf
}但要注意,static 變數不是 thread-safe 的,
如果多個 task 會同時呼叫這個函式,要加鎖或改用其他方式。
情況二:遞迴呼叫太深
// ❌ 遞迴解析 JSON,深度不可控
void parse_json(const char *json, int depth) {
char local_buf[256]; // 每層遞迴都吃 256 bytes
// ...
parse_json(nested_json, depth + 1);
}每一層遞迴都會在 Stack 上分配新的區域變數,
如果 JSON 巢狀很深,Stack 很快就滿了。
嵌入式盡量避免遞迴,
或是明確限制遞迴深度並加上檢查:
#define MAX_PARSE_DEPTH 8
void parse_json(const char *json, int depth) {
if (depth > MAX_PARSE_DEPTH) {
LOG_ERROR("JSON too deeply nested");
return;
}
// ...
}情況三:函式呼叫鏈太長
main()
→ init_system()
→ init_network()
→ wifi_connect()
→ tcp_handshake()
→ tls_negotiate()
→ crypto_verify()
→ sha256_compute()每一層函式都有自己的區域變數和返回位址,
呼叫鏈越長,Stack 用得越多。
這個比較難直接解決,
但可以透過測量(後面會說)來確認 Stack 用量是否安全。
情況四:ISR 的 Stack
在沒有 RTOS 的裸機系統,
中斷發生時,CPU 會把當前的 context 壓到 Stack 上,
然後跳去執行 ISR。
如果 ISR 本身也有區域變數,
這些都疊加在同一個 Stack 上。
如果 main 的 Stack 本來就快滿了,
這時候來一個中斷,就可能爆掉。
情況五:FreeRTOS 每個 Task 有自己的 Stack
// ❌ Stack 給太小
xTaskCreate(sensor_task, "Sensor", 128, NULL, 1, NULL);
// ^^^
// 128 words = 512 bytes(ARM 32-bit)FreeRTOS 的 Stack 大小單位是 word(ARM 上是 4 bytes),
128 words = 512 bytes,
如果 task 裡有稍微複雜的邏輯,很容易不夠。
怎麼知道 Stack 用了多少
方法一:Stack Painting(塗色法)
這是嵌入式最常用的方法。
原理是:在程式啟動時,把整個 Stack 填滿一個特殊的值(通常是 0xDEADBEEF 或 0xA5),
程式跑一段時間後,檢查還有多少 Stack 沒有被覆蓋。
// 在 startup code 裡,初始化 Stack 之前
extern uint32_t _stack_start; // linker script 定義的 Stack 底端
extern uint32_t _stack_end; // linker script 定義的 Stack 頂端
void stack_paint(void) {
uint32_t *p = &_stack_start;
while (p < &_stack_end) {
*p++ = 0xDEADBEEF;
}
}
// 之後可以查詢 Stack 的高水位線
size_t stack_get_unused(void) {
uint32_t *p = &_stack_start;
size_t unused = 0;
while (*p == 0xDEADBEEF) {
unused += sizeof(uint32_t);
p++;
}
return unused;
}定期呼叫 stack_get_unused(),
如果剩餘空間越來越少,要注意了。
方法二:FreeRTOS 內建的 High Water Mark
FreeRTOS 有內建 Stack 監控:
// 取得 task 的 Stack 剩餘最小值(歷史最低點)
UBaseType_t remaining = uxTaskGetStackHighWaterMark(NULL);
// NULL 代表查詢目前 task
// 回傳值單位是 word
LOG_INFO("Task stack remaining: %u words (%u bytes)",
remaining, remaining * sizeof(StackType_t));這個值是歷史最低點,
代表這個 task 從啟動到現在,Stack 最少剩下多少。
如果這個值很小(比如小於 20 words),
就要考慮增加 Stack 大小了。
可以在 monitor task 裡定期印出所有 task 的狀態:
void stack_monitor_task(void *pvParameters) {
for (;;) {
LOG_INFO("=== Stack Monitor ===");
LOG_INFO("sensor_task: %u words",
uxTaskGetStackHighWaterMark(sensor_task_handle));
LOG_INFO("network_task: %u words",
uxTaskGetStackHighWaterMark(network_task_handle));
LOG_INFO("mqtt_task: %u words",
uxTaskGetStackHighWaterMark(mqtt_task_handle));
vTaskDelay(pdMS_TO_TICKS(30000)); // 每 30 秒檢查一次
}
}方法三:讓 Stack Overflow 早點被發現
與其等 Stack Overflow 產生奇怪症狀,
不如讓它發生的時候立刻被抓到。
FreeRTOS Stack Overflow Hook:
// FreeRTOSConfig.h
#define configCHECK_FOR_STACK_OVERFLOW 2
// 1 = 只檢查 SP 是否超界
// 2 = 同時檢查 Stack 末端的 pattern 是否被覆蓋(更可靠)
// 實作 hook 函式
void vApplicationStackOverflowHook(TaskHandle_t xTask,
char *pcTaskName) {
// 這裡不能用正常的 log,因為 Stack 可能已經壞了
// 最保險的做法是直接 reset 或停在這裡讓 debugger 抓
__disable_irq();
while (1) {
// 停在這裡,讓 debugger 看到是哪個 task 出問題
}
}Cortex-M 的 MPU(Memory Protection Unit):
如果 MCU 有 MPU,
可以在 Stack 底端設置一個不可寫的保護區域,
Stack 一超界就立刻觸發 MemManage Fault,
比讓它默默覆蓋其他記憶體好多了。
一個真實的案例
之前有個專案,MCU 是 STM32,
程式跑幾個小時之後會莫名 reset。
GDB 抓到 reset 是因為 HardFault,
但 HardFault 的位址每次都不一樣,
完全找不到規律。
後來加了 Stack Painting,
發現 Stack 剩餘空間只剩 48 bytes,
幾乎是零。
追查原因,發現是某個函式在處理特定封包格式時,
會走到一條比較深的呼叫鏈,
加上那個函式有一個 512 bytes 的區域 buffer,
這條路徑的 Stack 用量比正常情況多了將近 800 bytes。
平常跑的封包不會觸發那條路徑,
所以測試都過了。
客戶的環境剛好有那種封包,跑幾個小時才出現。
解法:
- 把那個 512 bytes 的 buffer 改成 static
- Stack 大小從 2KB 增加到 4KB
- 加上 Stack 監控,定期印出剩餘空間
之後就再也沒有出現那個問題了。
說實話
Stack 問題在嵌入式是一個「不出事不知道,出事很難找」的類型。
我現在的習慣是,新專案一開始就把 Stack Painting 和監控加進去,
不要等出問題才來找。
Stack 大小的設定也不要太省,
多給個 50% 的餘裕,
幾百 bytes 的記憶體通常不是瓶頸,
但可以救你很多 debug 時間。
還有,每次加新功能之後,
都要看一下 Stack 的高水位線有沒有明顯變化,
養成習慣,就不會等到出貨之後才發現問題。
這篇的 Checklist
- [ ] 大型 buffer 沒有放在 Stack 上(改用 static 或全域)
- [ ] 遞迴呼叫有限制最大深度
- [ ] FreeRTOS task 的 Stack 大小有根據實際用量設定,不是隨便猜
- [ ] 有加 Stack Painting 或 FreeRTOS High Water Mark 監控
- [ ] FreeRTOS 有開
configCHECK_FOR_STACK_OVERFLOW - [ ] 有實作
vApplicationStackOverflowHook - [ ] 加新功能後有重新確認 Stack 用量